개요
대부분의 코드포스 라운드처럼 이번 라운드도 그리디한 생각과 문제를 얼마나 잘 분석하는지가 중점인 라운드였다.
A번
A번 문제: 그리디
숫자가 주어지고, 각 단계마다 숫자에서 $1$을 빼거나, $k$로 나누어 떨어지면 나눌 수 있다.
숫자를 $0$으로 만들려면 최소 몇 단계를 거쳐야하나?
풀이 보기
$n$부터 시작해서 $0$이 될 때까지 다음을 반복한다,
- $k$로 나눌 수 있을 때까지 뺀다. ($n - n \% k$)
- $0$이 아니면 $k$로 나눈다.
한 단계마다 최소 $k$씩 나누어지므로 한 쿼리 당 시간복잡도는 $\log n$이다.
소스코드 보기
include <bits/stdc++.h>
using namespace std;
#ifdef LOCAL_BOOKNU
#define debug(...) cerr << "[" << #__VA_ARGS__ << "]:", debug_out(__VA_ARGS__)
#else
#define debug(...) 42
#endif
// ........................macro.......................... //
#define FOR(i, f, n) for(int (i) = (f); (i) < (int)(n); ++(i))
#define RFOR(i, f, n) for(int (i) = (f); (i) >= (int)(n); --(i))
#define pb push_back
#define emb emplace_back
#define fi first
#define se second
#define ENDL '\n'
#define sz(A) (int)(A).size()
#define ALL(A) A.begin(), A.end()
#define UNIQUE(c) (c).resize(unique(ALL(c)) - (c).begin())
#define next next9876
#define prev prev1234
typedef pair<int, int> ii;
typedef pair<int, ii> iii;
typedef vector<int> vi;
typedef vector<vi> vvi;
typedef vector<ii> vii;
typedef vector<vii> vvii;
typedef long long i64;
typedef unsigned long long ui64;
// inline i64 GCD(i64 a, i64 b) { if(b == 0) return a; return GCD(b, a % b); }
inline int getidx(const vi& ar, int x) { return lower_bound(ALL(ar), x) - ar.begin(); } // 좌표 압축에 사용: 정렬된 ar에서 x의 idx를 찾음
inline i64 GCD(i64 a, i64 b) { i64 n; if(a < b) swap(a, b); while(b != 0) { n = a % b; a = b; b = n; } return a; }
inline i64 LCM(i64 a, i64 b) { if(a == 0 || b == 0) return GCD(a, b); return a / GCD(a, b) * b; }
inline i64 CEIL(i64 n, i64 d) { return n / d + (i64)(n % d != 0); } // 음수일 때 이상하게 작동할 수 있음.
inline i64 ROUND(i64 n, i64 d) { return n / d + (i64)((n % d) * 2 >= d); }
const i64 MOD = 1e9+7;
inline i64 POW(i64 a, i64 n) {
assert(0 <= n);
i64 ret;
for(ret = 1; n; a = a*a%MOD, n /= 2) { if(n%2) ret = ret*a%MOD; }
return ret;
}
template <class T> ostream& operator<<(ostream& os, vector<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class T> ostream& operator<<(ostream& os, set<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class L, class R> ostream& operator<<(ostream& os, pair<L, R> p) { return os << "(" << p.fi << "," << p.se << ")"; }
void debug_out() { cerr << endl; }
template <typename Head, typename... Tail> void debug_out(Head H, Tail... T) { cerr << " " << H, debug_out(T...); }
// ....................................................... //
i64 n, m;
void input() {
cin >> n >> m;
}
int solve() {
i64 ans = 0;
while(n) {
if(n%m != 0) {
ans += n%m;
n -= n%m;
}
if(n) {
n /= m;
++ans;
}
}
cout << ans << ENDL;
return 0;
}
// ................. main .................. //
void execute() {
int tt; cin >> tt;
while(tt--)
input(), solve();
}
int main(void) {
#ifdef LOCAL_BOOKNU
freopen("input.txt", "r", stdin);
// freopen("out.txt", "w", stdout);
#endif
cin.tie(0), ios_base::sync_with_stdio(false);
execute();
return 0;
}
// ......................................... //
B번
B번 문제: 그리디 구현
for n: $n$번 반복문end: 가장 가까운 반복문 종료add: $x$에 $1$을 더한다. 단, 덧셈 결과가 $2^{32}-1$보다 크면 오버플로가 발생한다.
위 3가지로 이루어진 코드가 있을 때, 코드 실행 후 $x$값을 출력하면 된다.
(단, 중간에 add연산 중 오버플로가 발생하면 OVERFLOW!!!를 출력한다.)
풀이 보기
구현이 은근히 까다로운 문제이다.
일단 기본적인 아이디어는 간단하다.
for n:스택을 통해 값을 계속 쌓아놓으며, 현재까지 쌓인 값의 곱들을 변수 $f$에 저장해두면 된다.end: 스택 맨 마지막을 뺀 후, $f$에서 그 값을 나누면 된다.add: $x$에 $f$를 더하면 된다.
구현에서 까다로운 점은, 중간에 $f$값 자체가 엄청나게 커질 수 있다는 것인데, 단순 계산으로는 최대 십진수로 $2 \cdot 10^{5}$ 자리수까지 커질 수 있어, BigInteger을 사용하더라도 그 연산 속도 때문에 시간 초과가 날 것이다.
또 까다로운 점이 $f$가 오버플로가 났다고 해서 답이 꼭 OVERFLOW!!!가 아니라 중간에 add만 이루어지지 않는다면 아무런 문제도 없다.
따라서 for n이 오버플로가 발생한 순간, 스택 포인터 변수에 오버플로가 발생한 변수의 포인터를 저장하고, 앞으로 for n문을 만나면 직접 $f$에 곱하지 않고 그냥 스택에만 쌓아두는 방식을 사용할 것이다.
또한 end를 통해 오버플로가 발생한 스택이 pop 된다면 그 때는 다시 스택 포인터 변수를 아무것도 가리키지 않는 상태로 둘 것이다.
만약 add 시 스택 포인터 변수가 무언가를 가리키고 있다면, 바로 OVERFLOW!!!를 출력하면 된다.
소스코드 보기
#include <bits/stdc++.h>
using namespace std;
#ifdef LOCAL_BOOKNU
#define debug(...) cerr << "[" << #__VA_ARGS__ << "]:", debug_out(__VA_ARGS__)
#else
#define debug(...) 42
#endif
// ........................macro.......................... //
#define FOR(i, f, n) for(int (i) = (f); (i) < (int)(n); ++(i))
#define RFOR(i, f, n) for(int (i) = (f); (i) >= (int)(n); --(i))
#define pb push_back
#define emb emplace_back
#define fi first
#define se second
#define ENDL '\n'
#define sz(A) (int)(A).size()
#define ALL(A) A.begin(), A.end()
#define UNIQUE(c) (c).resize(unique(ALL(c)) - (c).begin())
#define next next9876
#define prev prev1234
typedef pair<int, int> ii;
typedef pair<int, ii> iii;
typedef vector<int> vi;
typedef vector<vi> vvi;
typedef vector<ii> vii;
typedef vector<vii> vvii;
typedef long long i64;
typedef unsigned long long ui64;
// inline i64 GCD(i64 a, i64 b) { if(b == 0) return a; return GCD(b, a % b); }
inline int getidx(const vi& ar, int x) { return lower_bound(ALL(ar), x) - ar.begin(); } // 좌표 압축에 사용: 정렬된 ar에서 x의 idx를 찾음
inline i64 GCD(i64 a, i64 b) { i64 n; if(a < b) swap(a, b); while(b != 0) { n = a % b; a = b; b = n; } return a; }
inline i64 LCM(i64 a, i64 b) { if(a == 0 || b == 0) return GCD(a, b); return a / GCD(a, b) * b; }
inline i64 CEIL(i64 n, i64 d) { return n / d + (i64)(n % d != 0); } // 음수일 때 이상하게 작동할 수 있음.
inline i64 ROUND(i64 n, i64 d) { return n / d + (i64)((n % d) * 2 >= d); }
const i64 MOD = 0x7fffffffff;
inline i64 POW(i64 a, i64 n) {
assert(0 <= n);
i64 ret;
for(ret = 1; n; a = a*a%MOD, n /= 2) { if(n%2) ret = ret*a%MOD; }
return ret;
}
template <class T> ostream& operator<<(ostream& os, vector<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class T> ostream& operator<<(ostream& os, set<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class L, class R> ostream& operator<<(ostream& os, pair<L, R> p) { return os << "(" << p.fi << "," << p.se << ")"; }
void debug_out() { cerr << endl; }
template <typename Head, typename... Tail> void debug_out(Head H, Tail... T) { cerr << " " << H, debug_out(T...); }
// ....................................................... //
i64 lp, n, lim;
void input() {
cin >> lp;
}
int solve() {
lim = POW(2, 32)-1;
debug(lim);
stack<int> sta;
sta.push(1);
i64 f = 1;
int of = -1;
while(lp--) {
string t; cin >> t;
if(t == "add") {
n += f;
if(of != -1 || n > lim) {
cout << "OVERFLOW!!!" << ENDL;
return 0;
}
} else if(t == "for") {
i64 x; cin >> x;
if(of == -1) {
f *= x;
sta.push(x);
if(f > lim) of = sta.size();
} else sta.push(x);
} else {
if(of == -1) {
f /= sta.top();
sta.pop();
} else if(of == sta.size()) {
f /= sta.top();
sta.pop();
of = -1;
} else sta.pop();
}
}
cout << n << ENDL;
return 0;
}
// ................. main .................. //
void execute() {
input(), solve();
}
int main(void) {
#ifdef LOCAL_BOOKNU
freopen("input.txt", "r", stdin);
// freopen("out.txt", "w", stdout);
#endif
cin.tie(0), ios_base::sync_with_stdio(false);
execute();
return 0;
}
// ......................................... //
후기
구현이 좀 까다로워서 당황스러웠는데, 다행히 깔끔하게 처리해서 빠르게 넘어갈 수 있었다.
C번
C번 문제: 그리디
$x$축 위에 $n$개의 점 $x_i$들이 주어진다.
$x$축에서 아무 정수 좌표 $p$를 잡아 $d_i = abs(p - x_i)$들을 구했을 때 그 중 $k$번째로 작은 수를 최소화하고 싶다.
각 쿼리마다 죄표 $p$를 찾으면 된다.
풀이 보기
문제 자체가 겉으로 보기에는 상당히 복잡해보인다.
우선 $p$가 증가함에 따라 $f_k(p)$ 값이 1차 혹은 2차 함수 꼴이 되어 이분/삼분 탐색을 할 수 있나 살펴봤지만, 그런 특성은 없었다.
하지만 잘 살펴보니, $p$를 어디로 잡든 결국은 어느 두 점 $x_{i-1}, x_i$ 사이에 존재한다는 점을 알아냈다.
(물론 $x_1, x_n$ 바깥 쪽에 존재할 수 있지만, 그런 경우는 무조건 손해를 본다는 것을 쉽게 알 수 있다.)
이 때 $d_i$들은 항상 $p$를 기준으로 왼쪽, 오른쪽으로 연속된 $k$개의 점들이 선택된다는 것을 알 수 있다.
이것을 바꿔말하면, $[x_i…x_{i+k-1}]$들이 $p$를 기준으로 $d_1…d_k$가 될 수 있는 점들이라는 뜻이고, 결국 좌표들 중 연속된 $k$개 점들의 구간의 크기가 가장 작은 것의 중점을 $p$로 잡으면 $d_k$가 최소화 된다는 것을 알 수 있다.
소스코드 보기
#include <bits/stdc++.h>
using namespace std;
#ifdef LOCAL_BOOKNU
#define debug(...) cerr << "[" << #__VA_ARGS__ << "]:", debug_out(__VA_ARGS__)
#else
#define debug(...) 42
#endif
// ........................macro.......................... //
#define FOR(i, f, n) for(int (i) = (f); (i) < (int)(n); ++(i))
#define RFOR(i, f, n) for(int (i) = (f); (i) >= (int)(n); --(i))
#define pb push_back
#define emb emplace_back
#define fi first
#define se second
#define ENDL '\n'
#define sz(A) (int)(A).size()
#define ALL(A) A.begin(), A.end()
#define UNIQUE(c) (c).resize(unique(ALL(c)) - (c).begin())
#define next next9876
#define prev prev1234
typedef pair<int, int> ii;
typedef pair<int, ii> iii;
typedef vector<int> vi;
typedef vector<vi> vvi;
typedef vector<ii> vii;
typedef vector<vii> vvii;
typedef long long i64;
typedef unsigned long long ui64;
// inline i64 GCD(i64 a, i64 b) { if(b == 0) return a; return GCD(b, a % b); }
inline int getidx(const vi& ar, int x) { return lower_bound(ALL(ar), x) - ar.begin(); } // 좌표 압축에 사용: 정렬된 ar에서 x의 idx를 찾음
inline i64 GCD(i64 a, i64 b) { i64 n; if(a < b) swap(a, b); while(b != 0) { n = a % b; a = b; b = n; } return a; }
inline i64 LCM(i64 a, i64 b) { if(a == 0 || b == 0) return GCD(a, b); return a / GCD(a, b) * b; }
inline i64 CEIL(i64 n, i64 d) { return n / d + (i64)(n % d != 0); } // 음수일 때 이상하게 작동할 수 있음.
inline i64 ROUND(i64 n, i64 d) { return n / d + (i64)((n % d) * 2 >= d); }
const i64 MOD = 1e9+7;
inline i64 POW(i64 a, i64 n) {
assert(0 <= n);
i64 ret;
for(ret = 1; n; a = a*a%MOD, n /= 2) { if(n%2) ret = ret*a%MOD; }
return ret;
}
template <class T> ostream& operator<<(ostream& os, vector<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class T> ostream& operator<<(ostream& os, set<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class L, class R> ostream& operator<<(ostream& os, pair<L, R> p) { return os << "(" << p.fi << "," << p.se << ")"; }
void debug_out() { cerr << endl; }
template <typename Head, typename... Tail> void debug_out(Head H, Tail... T) { cerr << " " << H, debug_out(T...); }
// ....................................................... //
const int MAXN = 2e5+10;
i64 n, k, ar[MAXN];
void input() {
cin >> n >> k;
FOR(i, 0, n) cin >> ar[i];
}
int solve() {
i64 res = -1, cur = -1;
FOR(i, 0, n-k) {
if(res == -1 || cur > ar[i+k] - ar[i]) {
res = i, cur = ar[i+k] - ar[i];
}
}
cout << (ar[res+k] + ar[res]) / 2 << ENDL;
return 0;
}
// ................. main .................. //
void execute() {
int tt; cin >> tt;
while(tt--)
input(), solve();
}
int main(void) {
#ifdef LOCAL_BOOKNU
freopen("input.txt", "r", stdin);
// freopen("out.txt", "w", stdout);
#endif
cin.tie(0), ios_base::sync_with_stdio(false);
execute();
return 0;
}
// ......................................... //
D번
D번 문제: 그리디 정렬
$n$개의 수로 이루어진 배열이 주어지고, 이것을 $k$개의 최소한 원소를 $1$개 이상씩 가지고 있는 연속된 부분 배열로 나누어야 한다.
(물론 모든 배열의 원소들은 정확히 하나의 부분 배열에 속해야 한다.)
이 때, $f(i)$를 $a_i$가 속한 부분 배열의 idx라고 할 때 $\sum\limits_{i=1}^n{a_i \cdot f(i)}$ 이 최대가 되도록 부분 배열들을 나누고, 그 값을 찾아야한다.
(부분 배열의 idx는 좌측부터 $1$부터 증가하는 순으로 부여된다.)
풀이 보기
우선 위의 식을 개념적으로 풀어서 이해하면, 일단 세그먼트 단위로 쪼갠 후, 각 세그먼트에 들어있는 원소들의 합에 세그먼트 idx를 곱한것들의 합을 구하는 것으로 바뀐다. 즉,
이것을 그림으로 나타내면 다음과 같다.

하지만 여기서 한 걸음 나아가 관찰 할 수 있는 중요한 사실이 있는데, 세그먼트의 idx는 $1$에서부터 증가한다는 것을 이용해 위의 식을 일종의 누적 합으로 표현할 수 있다.
즉, 다음 그림과 같은 형태다.
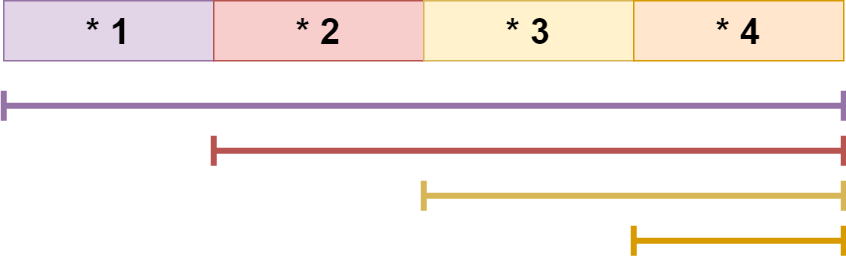
이것을 이용해 배열의 끝부분부터 시작하는 누적 합을 구해 우선 세그먼트 $1$은 배열의 전체를 커버하니까 따로 빼서 더하고, 나머지 누적합 중 큰 순으로 $k-1$개를 더하면 그게 바로 최대값이 된다.
소스코드 보기
#include <bits/stdc++.h>
using namespace std;
#ifdef LOCAL_BOOKNU
#define debug(...) cerr << "[" << #__VA_ARGS__ << "]:", debug_out(__VA_ARGS__)
#else
#define debug(...) 42
#endif
// ........................macro.......................... //
#define FOR(i, f, n) for(int (i) = (f); (i) < (int)(n); ++(i))
#define RFOR(i, f, n) for(int (i) = (f); (i) >= (int)(n); --(i))
#define pb push_back
#define emb emplace_back
#define fi first
#define se second
#define ENDL '\n'
#define sz(A) (int)(A).size()
#define ALL(A) A.begin(), A.end()
#define UNIQUE(c) (c).resize(unique(ALL(c)) - (c).begin())
#define next next9876
#define prev prev1234
typedef pair<int, int> ii;
typedef pair<int, ii> iii;
typedef vector<int> vi;
typedef vector<vi> vvi;
typedef vector<ii> vii;
typedef vector<vii> vvii;
typedef long long i64;
typedef unsigned long long ui64;
// inline i64 GCD(i64 a, i64 b) { if(b == 0) return a; return GCD(b, a % b); }
inline int getidx(const vi& ar, int x) { return lower_bound(ALL(ar), x) - ar.begin(); } // 좌표 압축에 사용: 정렬된 ar에서 x의 idx를 찾음
inline i64 GCD(i64 a, i64 b) { i64 n; if(a < b) swap(a, b); while(b != 0) { n = a % b; a = b; b = n; } return a; }
inline i64 LCM(i64 a, i64 b) { if(a == 0 || b == 0) return GCD(a, b); return a / GCD(a, b) * b; }
inline i64 CEIL(i64 n, i64 d) { return n / d + (i64)(n % d != 0); } // 음수일 때 이상하게 작동할 수 있음.
inline i64 ROUND(i64 n, i64 d) { return n / d + (i64)((n % d) * 2 >= d); }
const i64 MOD = 1e9+7;
inline i64 POW(i64 a, i64 n) {
assert(0 <= n);
i64 ret;
for(ret = 1; n; a = a*a%MOD, n /= 2) { if(n%2) ret = ret*a%MOD; }
return ret;
}
template <class T> ostream& operator<<(ostream& os, vector<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class T> ostream& operator<<(ostream& os, set<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class L, class R> ostream& operator<<(ostream& os, pair<L, R> p) { return os << "(" << p.fi << "," << p.se << ")"; }
void debug_out() { cerr << endl; }
template <typename Head, typename... Tail> void debug_out(Head H, Tail... T) { cerr << " " << H, debug_out(T...); }
// ....................................................... //
const int MAXN = 3e5+10;
i64 n, k, ar[MAXN], ps[MAXN];
void input() {
cin >> n >> k;
RFOR(i, n-1, 0) cin >> ar[i];
}
int solve() {
FOR(i, 0, n) ps[i] = (i ? ps[i-1] : 0) + ar[i];
i64 ans = ps[n-1];
sort(ps, ps + n - 1, greater<i64>());
FOR(i, 0, k-1) ans += ps[i];
cout << ans << ENDL;
return 0;
}
// ................. main .................. //
void execute() {
input(), solve();
}
int main(void) {
#ifdef LOCAL_BOOKNU
freopen("input.txt", "r", stdin);
// freopen("out.txt", "w", stdout);
#endif
cin.tie(0), ios_base::sync_with_stdio(false);
execute();
return 0;
}
// ......................................... //
후기
컨테스트 도중 잠깐 보다가 생각나는 아이디어가 없어서 E번으로 넘어갔는데, 컨테스트가 끝난 후 E를 풀고 자려고 누웠을 때 잠깐 생각했더니 아이디어가 떠올랐다.
조금만 더 생각했으면 적어도 이 문제는 풀 수 있었는데 상당히 아쉽다.
E번
E번 문제: 이분탐색 구간 겹치기
$n$개의 좌표 세그먼트 $[s_i, e_i]$들이 주어진다.
$m$개의 쿼리가 주어지는데, 주어진 세그먼트들을 이용해 $[x, y]$구간을 덮을 수 있는지, 덮을 수 있다면 최소로 선택할 때 몇 개의 세그먼트가 필요한지를 구하는 문제이다.
풀이 보기
구간의 전처리
우선 구간의 겹침에 대해 다루는 문제들에서 가장 많이 배제되는 경우를 생각해보자.
그리디하게 아래 그림에서 Seg가 존재할 때 P1 P2 P3를 유지시켜야 할 필요가 있을까?
Seg가 해당 구간들을 전부 덮고도 남으니, 당연히 이들을 선택할 바에야 Seg를 선택하는 것이 이득이라고 볼 수 있다.

이런 경우들을 배제하면, 남은 세그먼트들은 어떤 형태가 될까?
편의성을 위해 구간들을 시작점이 작은 순, 시작점이 같으면 끝 점이 큰 순으로 정렬하고, 순차적으로 처리한다고 하자.
이 때, 현재 구간을 추가할지 말지는 이전 구간보다 시작점이 크고, 끝 점도 큰 경우만 선택하면 된다.
왜 시작점이 같은 경우, 끝 점이 같거나 작은 경우일 때는 배제하는지는 다음 그림을 보면 쉽게 이해할 수 있다.

현재 구간을 선택했을 때 다음에 선택할 구간을 찾기
현재 구간 $s_i$를 선택했고, 아직은 더 커버를 해야지만 $[x, y]$를 완전히 덮을 수 있다고 할 때, 다음에는 어떤 구간을 선택하는게 이득일까?
당연하겠지만, $s_i$와 겹치면서(중간에 빈 틈이 없으면서) 끝 점이 가장 큰 구간을 선택하는 것이 가장 이득일 것이다.
그림으로 보면 빨간색 구간을 진한 파란색 구간의 다음 구간으로 선택할 것이다.

우리는 마치 그래프처럼 이런 구간의 다음 구간을 방향성 있는 간선처럼 연결할 것이고, 결국은 이 그래프는 DAG 형태가 된다.
이 때, $i$번째 구간의 다음 구간을 편의상 $edg[i]$라고 부르겠다.
그러나 각 구간마다 $edg[i]$를 구하는 일을 최대 $O(\log n)$시간만에 할 수 있어야 하는데, 이것은 이분 탐색을 이용해 쉽게 해결할 수 있다.
“$seg[i]$와 겹치면서 가장 끝 점이 먼 구간”을 찾는 것은 마치 $1$이 연속되다가 $0$이 나타나는 일종의 감소 함수에서 $1$이 나타나는 경우 중 $x$값이 가장 큰 경우를 찾는것과 비슷하기 때문에 이분 탐색으로 쉽게 구할 수 있다.
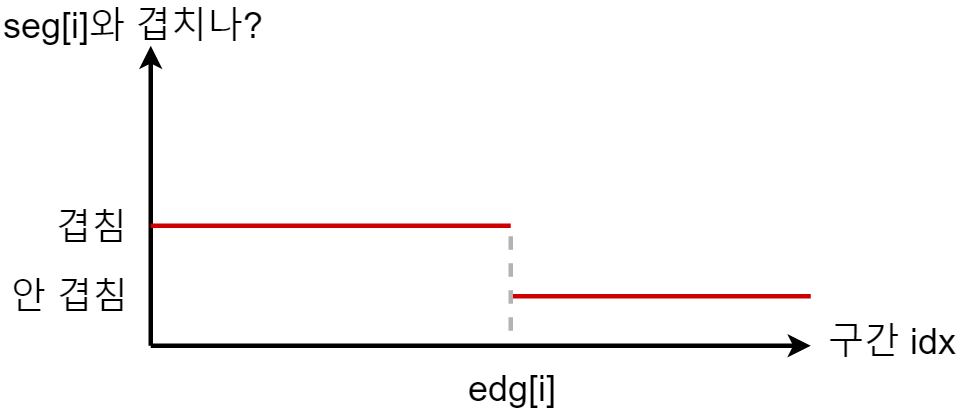
연속된 구간들의 묶음
이런 $edg[i]$ 정보들을 이용하면, 서로 연속된 구간들의 그룹을 쉽게 알 수 있다.
즉, 다음 그림과 같은 그룹들을 얻는 것이다.
이 그룹 정보를 얻어두면 나중에 $[x, y]$를 구간들을 이용해 완전히 덮을 수 있는지 여부를 확인할 수 있다.
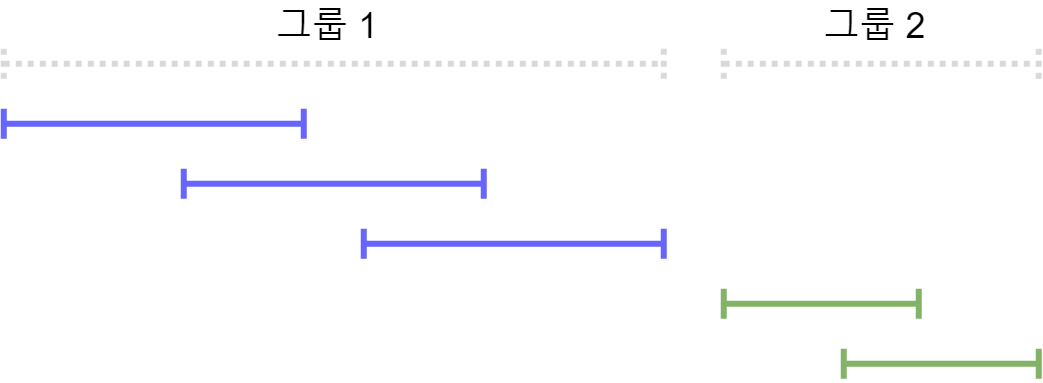
이런 그룹들을 얻는 방법은 간단하다. $i=0$에서부터 시작해 $edg[i]$를 타고 가며 그루핑하면 되는데, 만약 $edg[i] = i$인 경우 다음 겹치는 구간이 없으므로 이 때 그루핑을 해주면 된다.
이런 그룹들의 정보를 편의상 $rng[i]$라고 부르겠다. (range)
구간들로 특정 범위를 완전히 덮을 수 있는지 확인
실제 쿼리를 받을 때, 우선 $[x, y]$를 구간들로 덮을 수 있는지를 $O(\log n)$만에 확인해야한다.
이것 역시 이분 탐색을 통해 알아낼 수 있는데, 우선 $[x, y]$를 완전히 덮는 구간이 존재한다면 유일하다.
따라서, $rng$를 이분 탐색을 통해 탐색하는데, “$x$보다 시작점이 작은 $rng$중 가장 $idx$가 큰 것”을 찾아서 그것이 $[x, y]$를 완전히 포함하는지 보면 된다.
범위를 완전히 덮는 최소 구간 수 구하기
위의 사실이 확인되었다면, 이제 최소값을 알아내야한다.
위에서 무조건 $edg[i]$를 타고 구간을 덮어가는게 가장 이득이라는건 알았는데, 매번 $edg[i]$를 타고 가면 $O(n)$의 시간이 걸리기 때문에 $O(\log^2n)$방법을 생각해야 한다.
이것 역시 이분 탐색으로 구할 수 있는데, “$[x, y]$를 덮는 연속된 구간들 중 그 index 거리가 가장 작은 경우”를 구하면 된다.
이 때 index 거리란 “$i$에서 $edg$를 타고 간 횟수”를 편하게 부른 말이다.
하지만 위의 이분 탐색을 구현하려면 “$i$에서 $k$번 $edg$를 타고 갔을 때 나오는 구간”을 $O(\log n)$에 알아낼 수 있어야 한다.
이것을 위해 DP를 이용한 LCA아이디어를 차용할 것인데, 쉽게 말해 “$edg[i][j] =$ $seg[i]$에서 $edg$를 타고 $2^j$번 이동했을 때의 $seg$번호”를 전처리해두고, 이것을 이용해 $O(\log n)$번에 구간으로 찾아가는 것이다.
결국 이분탐색을 해서 얻어진index 거리$+ 1$이 해당 쿼리의 답이 된다.
소스코드 보기
#include <bits/stdc++.h>
using namespace std;
#ifdef LOCAL_BOOKNU
#define debug(...) cerr << "[" << #__VA_ARGS__ << "]:", debug_out(__VA_ARGS__)
#else
#define debug(...) 42
#endif
// ........................macro.......................... //
#define FOR(i, f, n) for(int (i) = (f); (i) < (int)(n); ++(i))
#define RFOR(i, f, n) for(int (i) = (f); (i) >= (int)(n); --(i))
#define pb push_back
#define emb emplace_back
#define fi first
#define se second
#define ENDL '\n'
#define sz(A) (int)(A).size()
#define ALL(A) A.begin(), A.end()
#define UNIQUE(c) (c).resize(unique(ALL(c)) - (c).begin())
#define next next9876
#define prev prev1234
typedef pair<int, int> ii;
typedef pair<int, ii> iii;
typedef vector<int> vi;
typedef vector<vi> vvi;
typedef vector<ii> vii;
typedef vector<vii> vvii;
typedef long long i64;
typedef unsigned long long ui64;
// inline i64 GCD(i64 a, i64 b) { if(b == 0) return a; return GCD(b, a % b); }
inline int getidx(const vi& ar, int x) { return lower_bound(ALL(ar), x) - ar.begin(); } // 좌표 압축에 사용: 정렬된 ar에서 x의 idx를 찾음
inline i64 GCD(i64 a, i64 b) { i64 n; if(a < b) swap(a, b); while(b != 0) { n = a % b; a = b; b = n; } return a; }
inline i64 LCM(i64 a, i64 b) { if(a == 0 || b == 0) return GCD(a, b); return a / GCD(a, b) * b; }
inline i64 CEIL(i64 n, i64 d) { return n / d + (i64)(n % d != 0); } // 음수일 때 이상하게 작동할 수 있음.
inline i64 ROUND(i64 n, i64 d) { return n / d + (i64)((n % d) * 2 >= d); }
const i64 MOD = 1e9+7;
inline i64 POW(i64 a, i64 n) {
assert(0 <= n);
i64 ret;
for(ret = 1; n; a = a*a%MOD, n /= 2) { if(n%2) ret = ret*a%MOD; }
return ret;
}
template <class T> ostream& operator<<(ostream& os, vector<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class T> ostream& operator<<(ostream& os, set<T> v) {
os << "[";
int cnt = 0;
for(auto vv : v) { os << vv; if(++cnt < v.size()) os << ","; }
return os << "]";
}
template <class L, class R> ostream& operator<<(ostream& os, pair<L, R> p) { return os << "(" << p.fi << "," << p.se << ")"; }
void debug_out() { cerr << endl; }
template <typename Head, typename... Tail> void debug_out(Head H, Tail... T) { cerr << " " << H, debug_out(T...); }
// ....................................................... //
// seg들을 x[i-1] < x[i] && y[i-1] < y[i] 형태가 되도록 걸러낸 후
// 각 정점에서 이어져있으면서 e가 가장 먼 edg들을 구한다.
// 또한 특정 범위를 모두 칠할 수 있는지를 알아내기 위해 건너건너 이어져서 뭉터기가 되는 rng들을 구해놓는다.
// 이제 매 쿼리마다 [s, e]가 완전히 포함되는 rng가 있는지를 이분 탐색으로 찾아내고,
// 만약 그런게 있으면 [s, e] 구간의 시작점을 포함하면서 e가 최대한 큰 "시작 seg"를 이분 탐색으로 찾아낸다.
// 거기서 또 이분 탐색을 통해 "시작 seg"에서 [s, e]를 포함할 수 있도록 할 수 있는 가운데 최소로 가야할 dis를 역시 이분 탐색을 통해 찾는다.
// 그러나 한 단계씩 edg를 타고 가면 O(n)이 걸리니까 lca 아이디어를 도입해서 빠르게 dis만큼 가보도록 한다.
// Time Complexity : O(nlog^2n)
const int MAXN = 2e5+10, LOGN = 18;
int n, m, edg[MAXN][LOGN];
vii seg, rng; // rng : 뭉터기 seg 범위
ii ars[MAXN];
void input() {
cin >> n >> m;
FOR(i, 0, n) cin >> ars[i].first >> ars[i].second;
}
// 해당하는 rng를 찾는다.
// 없으면 -1 반환
int findrng(int x, int y) {
int s = 0, e = rng.size();
while(s + 1 < e) {
int mid = (s + e) / 2;
if(seg[rng[mid].first].first <= x) s = mid;
else e = mid;
}
if(seg[rng[s].first].first <= x && y <= seg[rng[s].second].second) return s;
return -1;
}
// start 지점을 찾는다.
// start 지점을 포함하면서 e가 가장 큰 지점을 반환.
int getstart(int x) {
int s = 0, e = seg.size();
while(s + 1 < e) {
int mid = (s + e) / 2;
if(seg[mid].first <= x) s = mid;
else e = mid;
}
return s;
}
// s에서 빠르게 dis 다음번째 정점을 찾는다.
int getnext(int s, int dis) {
FOR(j, 0, LOGN) {
if(dis&(1<<j)) s = edg[s][j];
}
return s;
}
int solve() {
sort(ars, ars + n, [](ii& x, ii& y) {
if(x.first == y.first) return x.second > y.second;
return x.first < y.first;
});
FOR(i, 0, n) {
if(!seg.size() || (seg.back().fi < ars[i].first && seg.back().second < ars[i].second)) seg.pb(ars[i]);
}
n = seg.size();
FOR(i, 0, n) {
auto it = lower_bound(ALL(seg), ii(seg[i].second, -1));
if(it == seg.end() || it->first > seg[i].second) --it;
edg[i][0] = it - seg.begin();
}
{
int p = 0;
FOR(i, 0, n) {
if(edg[i][0] == i) rng.pb({ p, i }), p = i+1;
}
}
FOR(j, 1, LOGN) {
FOR(i, 0, n) {
edg[i][j] = edg[edg[i][j-1]][j-1];
}
}
while(m--) {
int x, y; cin >> x >> y;
if(findrng(x, y) == -1) {
cout << -1 << ENDL;
continue;
}
int p = getstart(x), ans = 1;
int s = -1, e = n;
while(s + 1 < e) {
int mid = (s+e)/2, nxt = getnext(p, mid);
if(y <= seg[nxt].second) e = mid;
else s = mid;
}
cout << e+1 << ENDL;
}
return 0;
}
// ................. main .................. //
void execute() {
input(), solve();
}
int main(void) {
#ifdef LOCAL_BOOKNU
freopen("input.txt", "r", stdin);
// freopen("out.txt", "w", stdout);
#endif
cin.tie(0), ios_base::sync_with_stdio(false);
execute();
return 0;
}
// ......................................... //
후기
처음 생각하던 방향성은 맞았는데, 중간에 구현을 하다가 “결국 $seg[0]$부터 시작해 $edg$를 타고 갈 수 있는 구간들만 남기면 되지 않나?”라는 이상한 그리디 방법을 생각해버린 바람에 시간을 날리고 문제를 풀지 못했다.
그 사실을 컨테스트 끝나기 1분 전에 알아버려서 굉장히 아쉬웠다.
후기
- D번에 대해서 좀 더 생각하지 않은게 아쉽다.
- E번에서 중간에 이상한 방향으로 생각한게 아쉽다.
